Ingestão de Baixa Latência com Datastream
Criação de um pipeline de replicação de dados near real-time com redução de 98% nos custos.
Contexto
Desenvolvi uma arquitetura de ingestão de dados utilizando Change Data Capture (CDC) para replicar dados de um banco transacional (MySQL) para um ambiente analítico (BigQuery) de maneira rápida, confiável e econômica. A solução foi projetada para minimizar o tempo de latência e custos operacionais, oferecendo uma solução robusta e escalável.
Problema
A metodologia anterior gerava alto consumo de recursos do banco de dados transacional, elevando os custos de processamento.
Durante o processo de replicação, ocorriam perdas de dados, comprometendo a integridade e a confiabilidade da informação.
O tempo de replicação era excessivo para tabelas de grande volume, o que inviabilizava análises com dados atualizados em tempo real.
Solução e Contribuição
- Projetei e implementei uma solução nativa na Google Cloud, utilizando Datastream, Cloud Storage, Composer (Airflow) e BigQuery.
- Configurei a captura de logs binários (binlog) via CDC, exportando os dados no formato Avro para o Cloud Storage.
- Estruturei uma arquitetura em camadas — External Tables, Streaming Views e Raw Tables — garantindo acesso a dados em tempo real e ao mesmo tempo otimizado para análise em lotes.
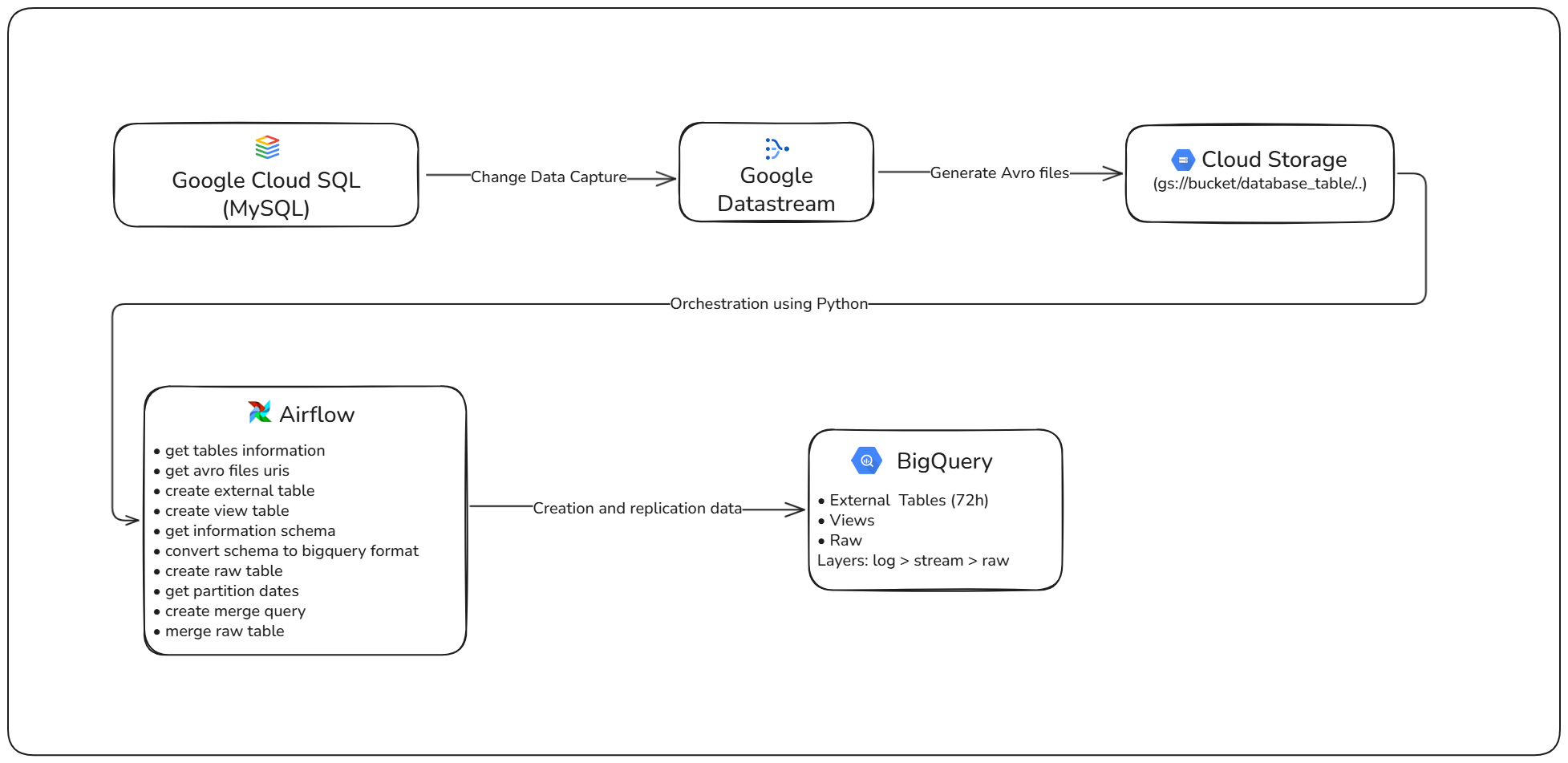
Diagrama de alto nível da arquitetura da solução do Ingestão de Baixa Latência com Datastream
Resultados e Impactos
- Redução de 98% nos custos de replicação de dados.
- Disponibilização dos dados para análise em minutos (near real-time), em vez de horas.
- Criação de uma arquitetura de ingestão modular, escalável e facilmente replicável para múltiplos clientes SaaS.
Tecnologias utilizadas
Detalhes técnicos
Arquitetura de Tabelas Externas e Views
O Datastream grava arquivos Avro diretamente no Cloud Storage. O BigQuery referencia esses arquivos por meio de Tabelas Externas, cobrindo dados de D-2 até o dia corrente, e constrói uma View que captura os registros mais recentes. Essa abordagem permite consultar dados atualizados em até 2 minutos, sem custos de processamento até o momento da execução da consulta. Em seguida, um processo de `merge select` transfere os dados para Raw Tables particionadas e clusterizadas, o que otimiza tanto os custos quanto o desempenho das consultas. A orquestração de todo o pipeline é feita por meio de uma DAG no Cloud Composer (Airflow).